
Anomaly detection, fraud detection, and outlier detection are the terms commonly heard in the A.I. world. While having different terms and suggesting different images to mind, they all reduce to the same mathematical problem, which is in simple terms, the process of detecting an entry among many entries, which does not seem to belong there.
For example, credit/debit card fraud detection, as a use case of anomaly detection, is the process of checking whether the incoming transaction request fits well with the user’s previous profile and behavior or not. Take this as an example: Joe is a hard-working man who works at a factory near NY. Every day he buys a cup of coffee from a local cafe, goes to work, buys lunch, and on his way home, he sometimes shops for groceries. He pays bills with his card and occasionally spends money on leisure, restaurants, cinema, etc.

One day, a transaction request is sent to Joe’s bank account to pay for a $30 payment at a pizza hut near Austin, TX. Not knowing whether this was Joe on a vacation or his card has gone missing, does this look like an anomalous transaction? Yes. What if someone starts paying $10 bills with Joe’s account on a “Card-holder-not-present” basis, e.g. online payment? The banking institute would want to stop these transactions and verify them with Joe, by SMS or Email.
These are obvious examples of anomalous transactions that seem identifiable by the naked eye. But as with every statistics problem, there are always non-trivial cases. How do we approach detecting them is the question I want to talk about.
Note that, there is no definite and certain answer to an anomaly detection problem, the answers are probabilistic and always depend on the perspective from which we are looking at the data.
Methods
I would classify the mathematical approaches to this problem into three categories: Easily explainable statistical methods, somewhat explainable classic machine learning methods, and the black-boxed deep learning methods.
Feature engineering
The process of feature engineering sets up the frame we are going to look at the data. It defines what we think is important and it is the process in which we introduce our intuition to the models. This step highly depends on the problem at hand but I am going to get deeper into it for the bank account example which we discussed earlier. What can help us decide whether it is Joe being Joe or his card or online credentials have gone missing? Here is a suggestive list:
- The total amount of money spent on this day: Looking at this and comparing it to Joe’s usual total per day, the model would learn how Joe usually behaves.
- The number of transactions on this day
- Amount
- Hour of the day
- Location
- …
Quoting this book, by Baesens et. al.,
A fraudulent account activity may involve spending as much as possible in a short space of time.
These are some examples that would need the banking institute to derive from different tables on their database on Joe. Of course, there are many other possible features for every problem, try and find them for your case.

Statistical Methods
The name might be a bit misleading since everything we are about to do is a statistical method right? But here I am focusing on simple statistics that can be explained in 5 minutes to for example a stakeholder, who might not understand complicated methods. A drawback of these methods is their incapability to handle categorical data, like the hour of the day feature. So in order to implement them, I would suggest applying them separately to each category. So we would be comparing during day transactions with each other and overnight transactions with each other.
- Modified Z-score:
Z-score is has a very simple idea behind it, how many standard deviations is this data point away from the mean of others? The higher it is, the more anomalous the data point. This definition has limits, it assumes the data is normally distributed and it is prone to outliers and would trigger if Joe decides to spend a little more than usual once in a while. Therefore we turn our looks to the modified Z-score, also recommended by Iglewicz and Hoaglin.
Modified Z-score uses median absolute deviation and is defined as follows:
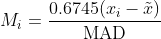
The authors suggest labeling the points with a modified Z-score of 3.5 or higher as anomalous.
2. Interquartile range:
As seen in boxplots visualizations, the distribution of data in a range can be visualized in quartiles, a nice description is available here.
In this method, the points between the first and the third quartile are normal points and the points outside them would be tagged as anomalous. You would be able to modify this to e.g. “intertentile” range, where instead of quartiles, you can use nth and mth tentile to label the data.
3. Histogram bins:
While being a famous way of data visualization, histograms can also be used in outlier detection. By calculating the bins for each sample and acquiring the histogram, we can flag the outlier points as anomalous. This is somewhat related to the Z-score metric.
Machine Learning Methods
In contrast to the methods described above, ML methods are far more sophisticated, a bit complicated, and able to handle categorical data (via preprocessing methods such as one-hot encoding, for example get_dummies in Pandas).
- k-nearest neighbors
kNN is a widely used ML algorithm which the fundamental logic behind it is the following: “the similar observations are in proximity to each other and outliers are usually lonely observations”. Using this, we can detect the points in a high-dimensional feature space that are the most “lonely”. It is greatly covered in sklearn library. By calculating the average distance of each data point from others, we can set a threshold to classify a certain proportion of them as anomalous, or even run Z-scoring on these distances and find the outliers.
2. One-class SVM
SVMs are a strong weapon in an ML toolkit. In short, they are hyperplanes in the feature space which divide points to different classes. In the context of anomaly detection, One-class SVMs learn what is “normal” and detect outliers and anomalous data based on that. Here is a thorough and complete article on the math behind it. One-class SVMs are available in sklearn’s SVM toolkit.
3. DBSCAN
DBSCAN is an unsupervised algorithm that detects densely packed regions of the space and marks the data points in low-density areas as anomalous. It is a widely used clustering method which has two hyperparameters to tune: Epsilon and min_samples, as defined in sklearn’s implementation.
Epsilon is the measure of how close the data points should be to each other to be part of one cluster, and min_samples the minimum number of points in a cluster.
4. LOF (Local outlier factor)
While having a similar logic to kNN and DBSCAN, LOF assigns a metric (LOF) to each datapoint, normal points would have a score somewhere between 1 and 1.5 while outliers having a higher score. It is also present in sklearn.
4. Isolations Forest
Isolation forest or iForest, is a very strong, probably the best method in big data, tool for anomaly detection. It is easily scalable and there is a great explanation here. It is the way-to-go for big data anomaly detection.

Deep Learning Methods
Finally, the fancy A.I. regions, where we end up with black boxes which perform well for the reasons we don’t know and judge the data based on reasons we can not interpret. The most famous DL anomaly detection method is the use of autoencoder networks.
Autoencoders
Autoencoders are networks which consist of two, well actually three, parts: The encoder, the latent space, the decoder. In mathematical terms, autoencoders learn the identity function (simply put: f(x)=x) on the dataset. Let’s say I input a large set of Joe’s transactions which I believe are not fraudulent. The network trains on taking transaction a, encoding it to the latent, lower-dimensional space, and then decoding it back to a space with the cardinality equal to the input space. For example, an input with 100 features would be reduced to a latent space with 30 features (this is encoding), then turn back into a 100 features representation. The neural network trains on minimizing the difference between the input and the output.
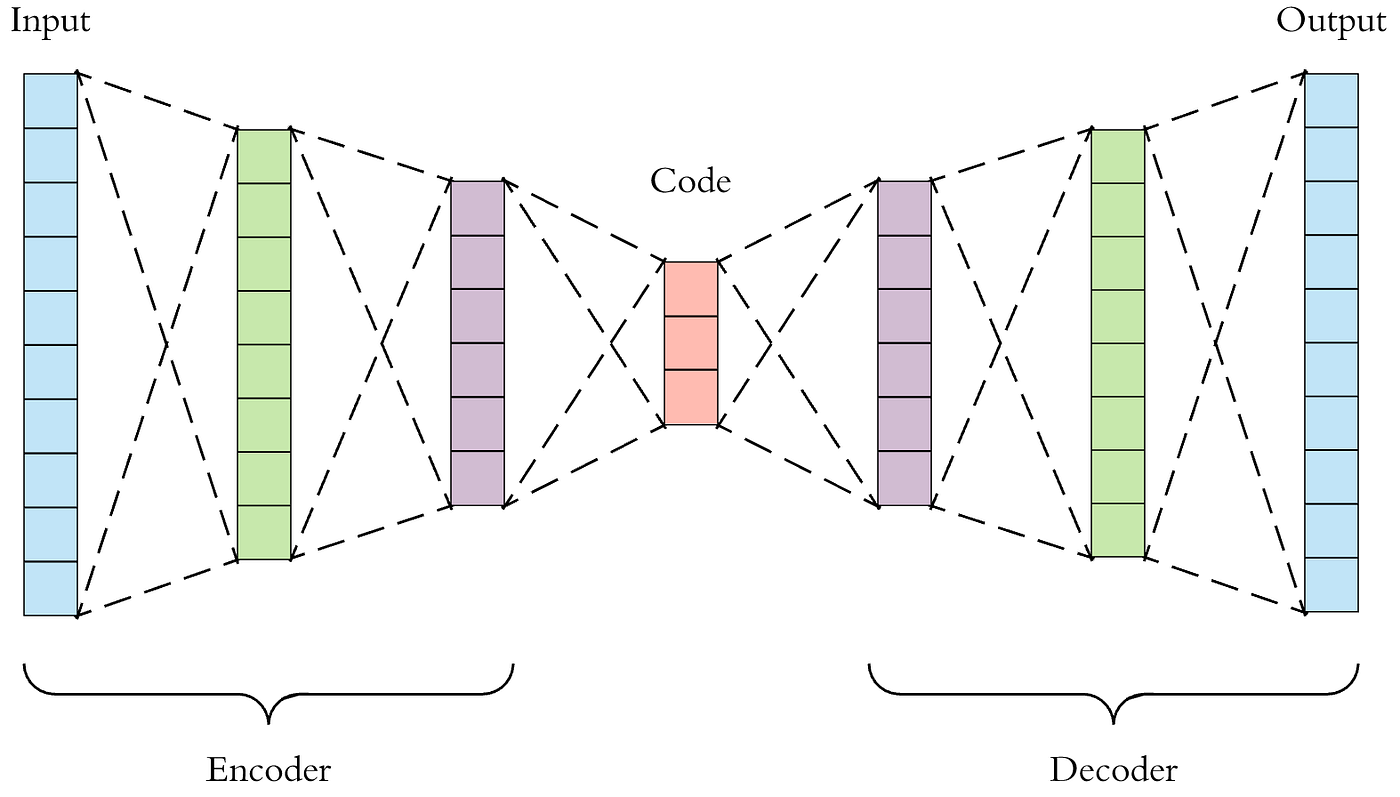
So it basically learns to give back whatever it has received. Now, after the training phase, if we show a normal entry to it, the network would be able to reconstruct it with low error, as it is similar to what we have trained the network with. But what if I input a slightly different entry? The reconstruction error would be higher, meaning that the network has not been able to reconstruct it very well. We can decide based on this metric, whether a data point is anomalous or not.
This was a quick review of the famous, available methods for anomaly detection. I would go deeper on some of them in the future and provide a hands-on example for detecting fraud in a sample dataset. Let me know what you think if there are any comments in your mind.




Leave a Reply